Python全栈系列43 分布式服务网络结构、数据处理与存储支持服务
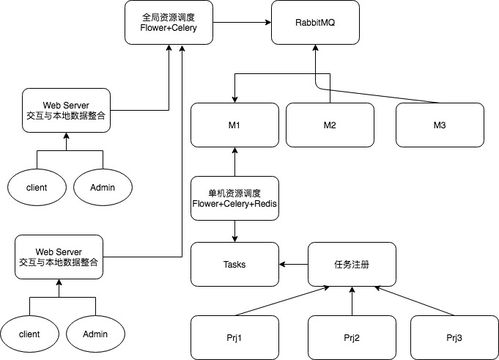
在构建现代、可扩展的Python全栈应用时,分布式服务网络结构与高效的数据处理和存储支持服务是两个核心支柱。它们共同决定了系统的性能、可靠性和未来的演进能力。
一、分布式服务网络结构
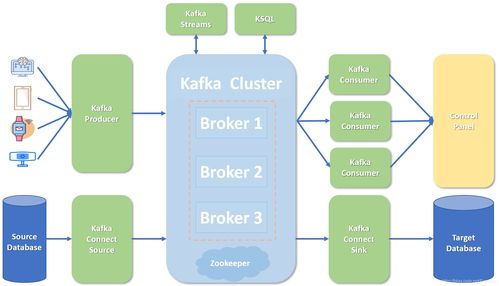
分布式架构的核心思想是将一个大型单体应用拆分为多个独立部署、协同工作的服务。这种结构带来了诸多优势,但也引入了新的复杂性。
- 常见网络拓扑结构
- 点对点 (Peer-to-Peer):服务之间直接通信,结构简单,但服务发现和负载均衡需自行管理。
- 客户端-服务器 (Client-Server):经典结构,客户端向明确的服务端发起请求。在微服务中,一个服务既是其他服务的客户端,也是自身领域的服务器。
- 星型/中心辐射型 (Hub-and-Spoke):所有服务通过一个中心节点(如API网关、消息总线)进行通信。这简化了客户端调用,但中心节点可能成为瓶颈和单点故障。
- 服务网格 (Service Mesh):这是当前的主流演进方向。通过在每个服务实例旁部署一个轻量级网络代理(Sidecar,如Envoy),形成专用的基础设施层,统一处理服务发现、负载均衡、熔断、限流、观测和安全通信(mTLS)等网络问题。Istio和Linkerd是代表性实现。对于Python技术栈,可以利用
service-mesh-python-sdk或通过Sidecar代理来集成。
- Python技术栈的关键组件
- API网关:作为系统的统一入口,处理路由、认证、限流等跨领域问题。常用框架有
FastAPI(高性能)、Django(功能全面)结合Django Ninja,或专用网关如Kong、APISIX。
- 服务发现与注册:服务启动时向注册中心(如
Consul、Etcd、ZooKeeper或Nacos)注册自身地址,消费者从注册中心获取可用服务列表。Python客户端库(如python-consul)可以方便地集成。
- 通信协议:
- RESTful HTTP/JSON:最通用,使用
requests、httpx(支持异步)库。
- gRPC:高性能RPC框架,基于HTTP/2和Protocol Buffers,适合服务间密集通信。使用
grpcio和grpcio-tools库。
- 异步消息队列:用于解耦和异步处理,使用
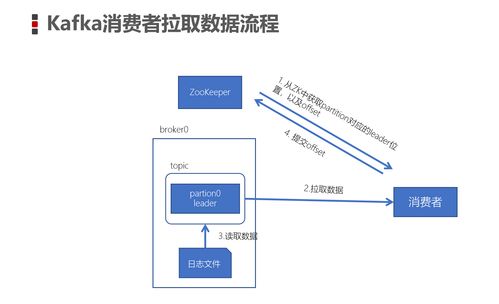
RabbitMQ(pika库)、Apache Kafka(confluent-kafka或aiokafka库)、Redis(celery任务队列)或NATS。
- 设计模式:网关路由、断路器(
pybreaker)、重试、回退、负载均衡(客户端或服务器端)等模式对构建健壮的网络至关重要。
二、数据处理与存储支持服务
数据处理服务是分布式系统的“引擎”,负责对数据进行清洗、转换、分析和存储,为上层应用提供动力。
- 数据处理流水线
- 批处理:适用于对时间不敏感的大规模数据。使用
Apache Spark(PySpark)或Dask进行分布式计算。工作流调度可使用Apache Airflow(纯Python编写)来定义、调度和监控复杂的批处理流水线。
- 流处理:适用于实时或近实时数据。使用
Apache Flink(通过PyFlink)、Apache Spark Streaming,或轻量级的Faust(基于Kafka和asyncio)。这些框架能处理无限数据流,支持窗口计算和状态管理。
2. 存储支持服务
根据数据特性和访问模式,选择合适的存储引擎,形成多模持久化策略。
- 结构化数据 (SQL):关系型数据,事务性强。
- 传统RDBMS:
PostgreSQL(功能丰富)、MySQL(应用广泛)。使用SQLAlchemyORM或异步的SQLModel、Tortoise-ORM,连接池用aiomysql/asyncpg。
- 云原生/分布式SQL:
CockroachDB、TiDB,提供水平扩展和强一致性。
- 半结构化/文档数据 (NoSQL):JSON文档,模式灵活。
MongoDB:使用pymongo或异步的motor驱动。
Elasticsearch:专长搜索和分析,使用elasticsearch-py客户端。
- 宽列存储 (NoSQL):海量数据,按列族存储。
Apache Cassandra、ScyllaDB:高写入、最终一致性,使用cassandra-driver。
- 键值存储 (NoSQL):极简模型,超高速度。
Redis:内存存储,用作缓存、消息队列、会话存储,使用redis-py或异步的aioredis。
etcd:用于配置存储和服务发现。
- 对象/Blob存储:存储图片、视频等二进制大对象。
Amazon S3、MinIO(自建S3兼容),使用boto3库。
- 时序数据:专门存储时间序列数据,如监控指标。
InfluxDB、TimescaleDB(基于PostgreSQL的扩展)。
- 图数据:存储实体间复杂关系。
Neo4j,使用neo4jPython驱动。
- 缓存策略
- 本地缓存:
lru_cache装饰器或cachetools库,适用于单进程内重复计算。
- 分布式缓存:
Redis或Memcached(pymemcache),作为应用层缓存,显著减轻数据库压力。
三、整合与实践:构建支持平台
在实际项目中,这些组件并非孤立存在,而是需要整合成一个统一的支持平台:
- 统一配置中心:使用
Consul、Etcd或Apollo管理所有服务的配置,实现动态更新。 - 可观测性:
- 日志聚合:使用
ELK Stack(Elasticsearch, Logstash, Kibana)或Loki,Python应用通过structlog或logging模块生成结构化日志。
- 指标监控:使用
Prometheus收集指标(通过prometheus-client库暴露),Grafana进行可视化。
- 分布式追踪:使用
Jaeger或Zipkin,通过opentelemetry-python库实现请求链路的全貌追踪。
- 数据访问层抽象:在业务服务与具体存储之间,构建一层数据访问服务或库,封装连接管理、分片逻辑、缓存策略和查询优化,使业务逻辑与存储技术解耦。
###
构建Python全栈分布式系统,需要精心设计其网络结构以实现服务间高效、可靠的通信,并搭建强大的数据处理与存储支持服务作为数据基石。通过API网关、服务网格管理网络复杂性,通过多模存储和批流一体处理引擎应对多样化的数据需求,再辅以配置中心、缓存和完整的可观测性体系,才能支撑起一个弹性、健壮且易于维护的现代化应用。随着业务增长,这套支持服务的能力将直接决定系统的天花板。
如若转载,请注明出处:http://www.mitaodiary.com/product/68.html
更新时间:2026-06-19 09:51:17