分布式文件存储SeaweedFS的数据存储设计与实现 数据处理与存储支持服务解析

在当今大数据时代,数据处理与存储支持服务已成为各类应用的核心基础。分布式文件存储系统SeaweedFS凭借其简洁高效的设计,为解决海量非结构化数据存储问题提供了强有力的支持。本文将深入探讨SeaweedFS在数据存储层面的设计与实现,揭示其如何为上层的数据处理提供坚实可靠的存储服务。
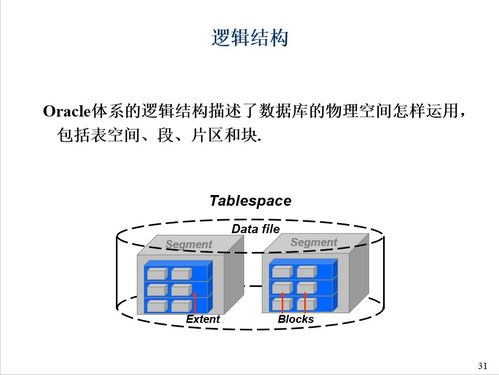
SeaweedFS的设计哲学是“简单而强大”,其核心架构由两部分组成:管理文件元数据的Master Server和实际存储文件数据的Volume Server。这种清晰的分层设计使得系统具有出色的可扩展性和高可用性。在数据存储层面,SeaweedFS采用了一种巧妙的设计:将文件存储抽象为一个个固定大小的“卷”(Volume),每个卷由多个数据块组成,支持高效的读写操作。
在数据存储的实现上,SeaweedFS采用了几项关键技术:
第一,智能数据分片与复制机制。SeaweedFS会自动将大文件分割成固定大小的数据块(默认为32MB),并将这些数据块分布到不同的Volume Server上存储。系统支持可配置的复制因子,确保数据的高可用性和容错能力。这种设计不仅提高了数据读写的并发性能,还通过数据冗余保障了数据安全性。
第二,高效的数据索引管理。Master Server采用轻量级设计,仅存储卷到Volume Server的映射关系,而不存储具体的文件元数据。文件ID直接编码了卷ID和文件在卷内的偏移量,这种设计大大减少了元数据管理的开销,使得Master Server可以轻松管理数十亿级别的文件。
第三,优化的数据访问路径。客户端在读写文件时,首先从Master Server获取卷的位置信息,然后直接与对应的Volume Server通信。这种去中心化的数据访问模式避免了单点瓶颈,显著提高了系统的吞吐能力。
第四,灵活的数据存储策略。SeaweedFS支持多种存储后端,包括本地文件系统、云存储服务等。Volume Server可以采用不同的存储介质和配置,满足不同场景下的性能与成本需求。
在数据处理支持方面,SeaweedFS提供了丰富的API接口,包括RESTful API和FUSE文件系统接口,使得各种数据处理框架(如Hadoop、Spark)可以轻松集成。系统还支持数据压缩、加密等特性,为敏感数据的处理提供安全保障。
SeaweedFS的数据存储设计充分考虑了实际运维需求。系统提供了详细的数据统计和监控接口,支持数据的均衡分布和热点数据的自动迁移。当存储节点出现故障时,系统能够自动检测并启动数据恢复流程,确保存储服务的连续性。
SeaweedFS通过简洁而高效的数据存储设计,为大规模数据处理应用提供了可靠的基础设施支持。其模块化的架构、智能的数据分布策略和丰富的API接口,使得它能够适应从传统企业应用到现代云原生环境的多样化需求。随着数据量的持续增长和处理需求的不断演进,SeaweedFS这类轻量级、高可扩展的分布式存储系统将在数据处理生态中扮演越来越重要的角色。
如若转载,请注明出处:http://www.mitaodiary.com/product/45.html
更新时间:2026-08-02 05:35:49